Objective
The objective is to forecast the price of an Airbnb listing using provided features and to automatically suggest comparable listings.
Motivation
The motivation behind this project is to enhance user experience within the platform and simplify the process for hosts to determine listing prices. By precisely forecasting listing prices using factors like location, amenities, and historical data, hosts can confidently establish appropriate pricing for their listings. Incorporating a recommendation system guarantees users receive customized suggestions that align with their preferences and needs, streamlining the booking process and enhancing overall satisfaction.
Skills: Pandas, NumPy, scikit-learn, Keras, TensorFlow
Dataset: Amsterdam Airbnb Dataset
The dataset contains two main files:
- listings_details.csv: contains details about available listings in Amsterdam including the neighborhood details, amenities, host details, listing description, price, score for the listing and so on. It has about 96 features.
- review_details.csv: contains reviews for available listings
Methodology
- Data Cleaning
- Dropped columns with more than 80% missing values.
- Dropped columns that would not be useful for price prediction - “jurisdiction_names” “is_business_travel_ready”, “host_has_profile_pic”, “host_identity_verified”, etc.
- Converted string type price variables to float.
- Filled missing values with appropriate values. Used ColumnTransformer for imputing.
- Exploratory Data Analysis
- Plotted various graphs to understand correlation between different features.
- Plotted a word cloud for listing description to understand the most common amenities.
- Performed clustering to understand the highest differentiating factors.
- Feature Engineering
- Converted categorical features to numerical using one hot encoding. This resulted in a total of 207 features.
- Performed feature selection to select 150 most important features to reduce noise in the dataset.
- Scaled dataset for
- Model Selection, Training and Evaluation
- Trained multiple ML models - linear, ridge, and lasso regression, bagging, extreme gradient boosting, random forest, and Artificial Neural Networks (ANN) to find the best price prediction model.
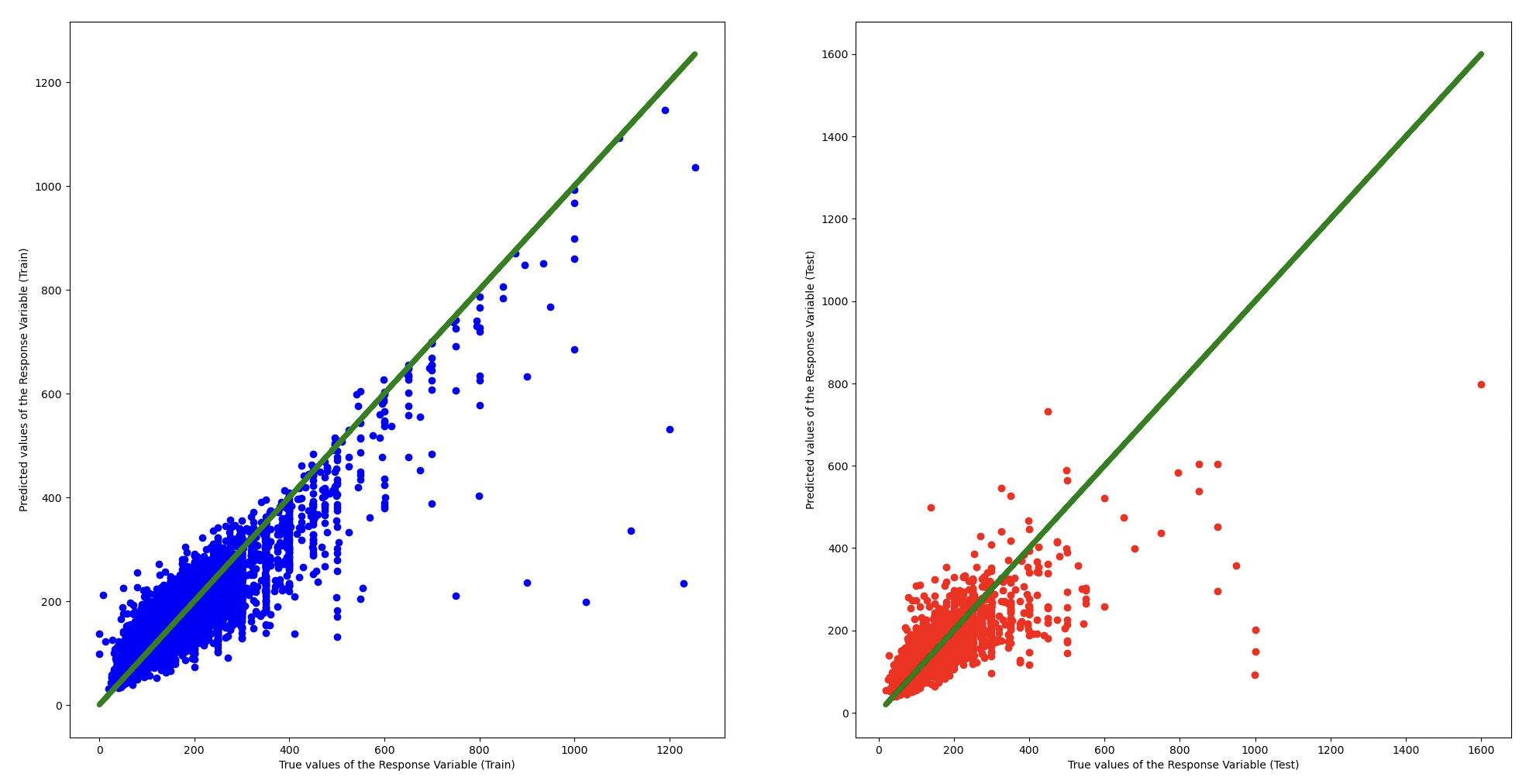
- XGB exhibited the highest performance with an R2 score of 60%.
- Model Evaluation and Hyperparameter Finetuning
- Evaluated the XGB Regressor model on testing dataset.
- Finetuned the hyperparameters of the XGB Regressor model using GridSearchCV.
- For testing dataset, the finetuned XGB Regressor model gave an R2 score of 50%.
For Recommendation
- Created a TF-IDF matrix for each unique identifier (id), encompassing both unigrams and bigrams.
- Utilized Cosine Similarity to compare TF-IDF matrices derived from listing unigrams and bigrams.
- Employed the resultant similarity scores to generate recommendations for listings based on their textual features.
Results