Objectives
- To check if the code contains any syntax errors.
- To identify the syntactical errors in the given Python code.
- To automate the process of fixing the syntax errors using ML.
- To use an encoder-decoder model for code correction.
- To use an encoder-decoder model for generating errors closer to real life errors
- Act as an illustration for a single programming language ( Python ) initially.
Motivation
Syntax errors plague new programmers as they struggle to learn computer programming. Even experienced programmers get frustrated by syntax errors, often resorting to erratically commenting their code out in the hope that they discover the location of the error that brought their development to a screeching halt. Syntax errors are annoying to programmers, and sometimes very hard to find. Even when the errors are detected and displayed, the complex interpreter error language is not understandable to novice programmers. There has been much work on trying to improve error location detection and error reporting.
Hence, to reduce the amount of time spent in understanding and correcting syntax errors needs to be minimized in order to maximize productivity. For this, developing a system that automatically detects the error location and predicts the correct fix for syntax errors is necessary.
Architecture Diagram
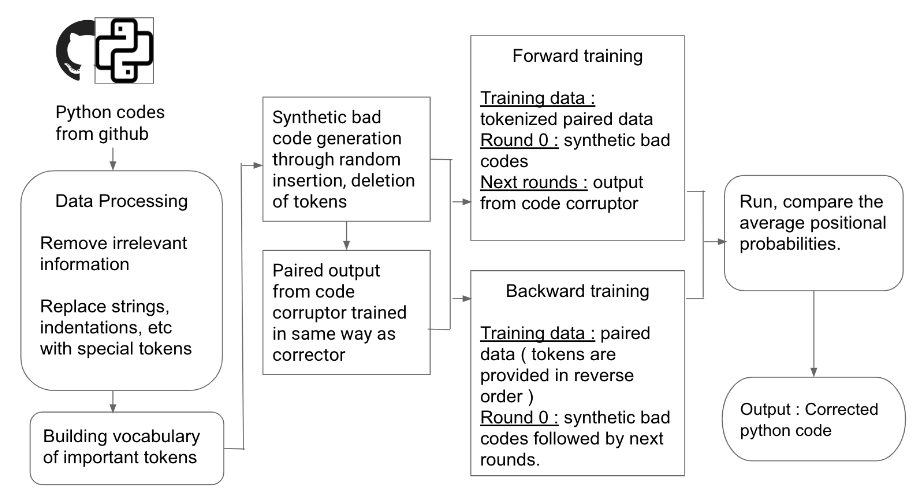
- A large dataset containing the syntactically correct Python code is extracted from GitHub public repositories.
- Data preprocessing includes tokenization of the input codes. Tokenization is necessary for providing a specific format of input to the models for training and testing. Then, clean and pre-process the data, removing any irrelevant information. Replace newline, indentation and dedentations with special tokens. Eg: Replace an indentation with special token ,dedent space with , newlines with . Vectorization is then performed so as to convert it into embeddings which would act as the exact inputs to the encoder decoder transformer model (corrector and code corruptor).
- A python vocabulary is then created. Vocabulary consists of the commonly used tokens in a language. A python vocabulary consists of python keywords(if, for, import) and symbols(“, (, [). This helps in recognizing the keywords that are used in codes. Recognition of keywords helps in eliminating these words with token during preprocessing. As a result, they will not be treated as variables.
- For training, we require a pair of good and bad codes. The syntactically correct codes(good codes) are collected from github. The syntactically wrong codes are generated by introducing random errors in the good codes. Mutation can be done using: Random Deletion: a token chosen at random from the input source file is deleted. Random Replacement: a token was chosen at ran-dom and replaced with a random token found from vocabulary. Random Insertion: a location in the source file is chosen at random and a random token found is inserted there.
- The correctors are trained first. For the corrector, a pair of bad and good code is given as input. We use the Fairseq toolkit for training the models. Fairseq is a sequence modeling toolkit for training custom models for translation, summarization, and other text generation tasks. The corrector is of two types: Forward corrector and Backward Corrector. Forward Corrector: predicts the next token based on prefix sequence Backward Corrector: predicts the next token based on suffix sequence
After training the correctors, for testing, we provide bad code as input to these models and the output is the corresponding good code.
This data generated from running the correctors is provided as input to the code corruptor. The main job of code corruptor is to generate syntactically wrong code from corresponding good codes. Training an ML model for this purpose ensures that the syntax errors introduced in the codes are similar to real life errors made by the programmers. We provide good code as input to this model and the output is the corresponding bad code generated by introducing random errors.
The process of training and testing the correctors and code corruptor is repeated until the required accuracy is obtained. The code from correctors is given as input to code corruptors and vice versa.
Encoder-Decoder Model
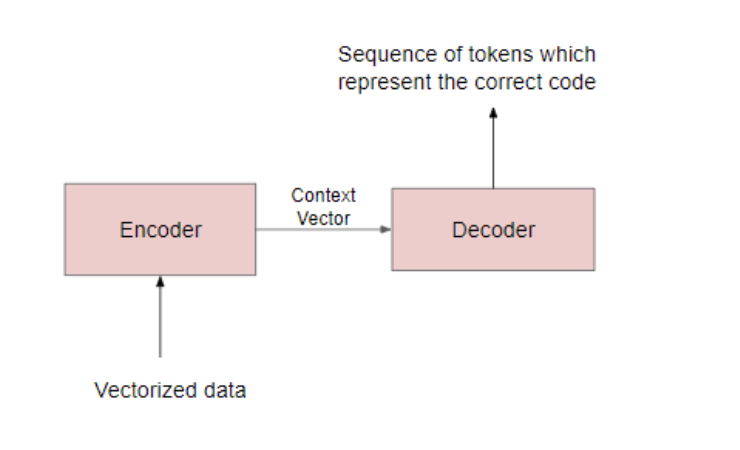
- Encoder: The encoder processes each token in the input-sequence. It tries to cram all the information about the input-sequence into a vector of fixed length i.e. the ‘context vector’. After going through all the tokens, the encoder passes this vector onto the decoder.
- Context vector: It encapsulates the whole meaning of the input-sequence and helps the decoder make accurate predictions.
- Decoder: The decoder reads the context vector and tries to predict the target-sequence token by token.
Forward & Backward Correctors
Forward Corrector:
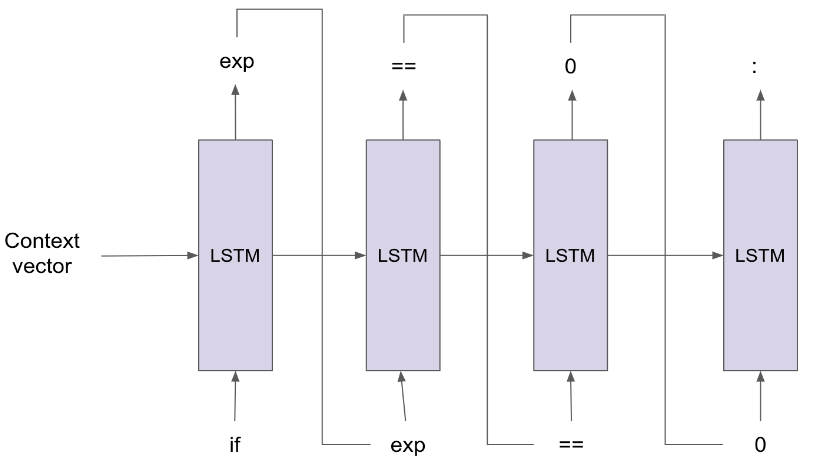
The forward corrector predicts the next token based on the prefix sequence. As shown in the figure, the input to the forward corrector is a context vector generated by the encoder. This context vector encapsulates all the information of the bad code in it. Here, suppose we want to find what comes after an expression in the if statement, we start from the token “if”. Then the next token “exp” is predicted by the forward corrector and then finally we get the “==” token as the next prediction.
Backward Corrector:
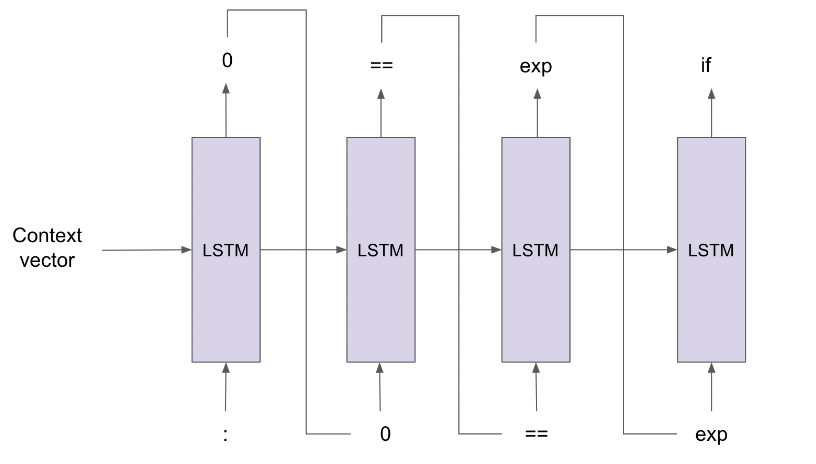
The backward corrector, unlike the forwardcorrector which uses the prefix sequence to make predictions, predicts the next token based on the suffix sequence. As shown in the figure, the input to the backward corrector is a context vector generated by the encoder. This context vector encapsulates all the information of the bad code in it. The code is in reverse format. Here, suppose we want to find what comes after an expression in the if statement, we start from the token “:”. Then the next token “0” is predicted by the backward corrector and then we get the “==” token as the next prediction. This token is before the “exp” token.
Why forward and backward corrector?
The two correctors are useful in the following case: Suppose you have a statement “if (i == 0 && j==1):” The forward corrector will start from the “if” token and the backward corrector will start from the “:” token. Then each token will be predicted by both the correctors.
The forward corrector, after encountering “0” might predict a “)” token. This would indicate that the input code is wrong, while in reality it is a syntactically correct code. As a softmax function is used in encoder decoder transformers, the next high probability token predicted by the forward corrector will be “&”.
On the other hand, the backward corrector will start from the code end. After encountering the “j” token, it might predict the “(“ token. This would indicate that the input code is wrong, while in reality it is a syntactically correct code. As a softmax function is used in encoder decoder transformers, the next high probability token predicted by the backward corrector will be “&”.
As a result, both correctors predicted the “&” token with the second highest probability. They agree on a single token. This means that the next token based on the prefix and suffix sequence will be “&”. This will be the final predicted token. Whichever code has the highest probability of being the correct version of the input code will be provided as output to the user.
Training and Testing
- Encoder
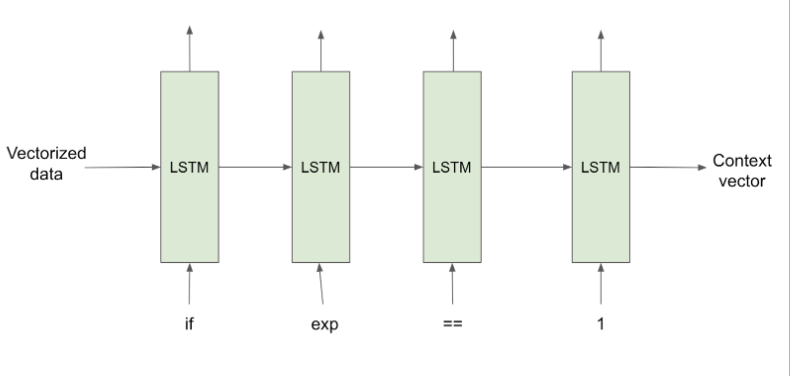
The working of the encoder is the same in both the training and testing phase. It accepts each token/word of the input-sequence one by one and sends the final states to the decoder. Its parameters are updated using backpropagation over time.
- Decoder The decoder block is an LSTM cell. The initial states (h₀, c₀) of the decoder are set to the final states (hₜ, cₜ) of the encoder. These act as the ‘context’ vector and help the decoder produce the desired target-sequence.
Training the decoder model:
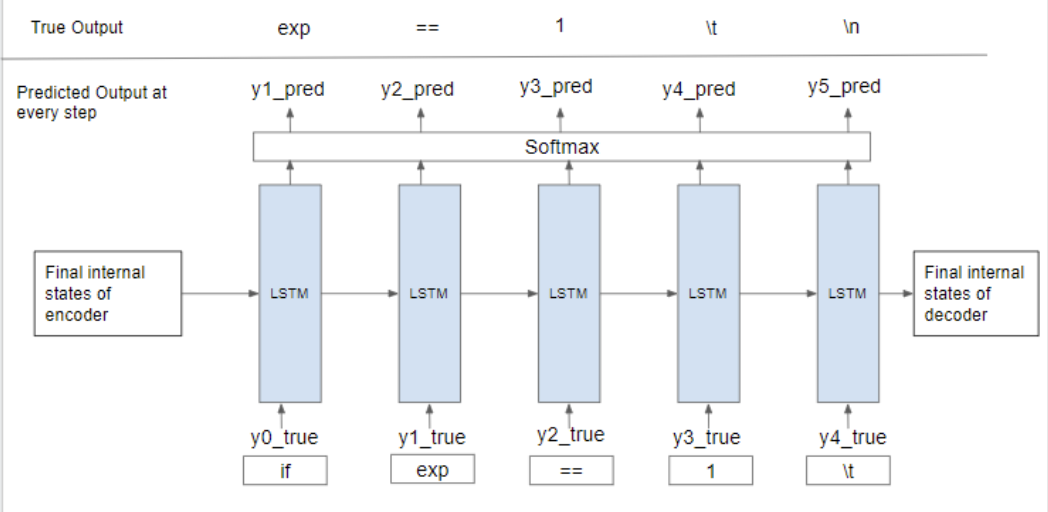
To train the decoder model, a technique called “Teacher Forcing” in which we feed the true output/token (and not the predicted output/token) from the previous time-step as input to the current time-step.
Time step 1:
The vector [1 0 0 0 0] for the token ‘if’ is fed as the input vector. Here the expected output is an expression. But as the model has just started training, it will output something random. Let the predicted value at time-step 1 be y1_pred = [0.02 0.12 0.36 0.1 0.3 0.1] meaning it predicts the 1st token to be ‘==’. Now, should we use this y1_pred as the input at time-step 2, the model would be wrongly trained.
Thus, teacher forcing was introduced to rectify this. In this, we feed the true output/token (and not the predicted output) from the previous time-step as input to the current time-step. That means the input to the time-step 2 will be y1_true = [0 1 0 0 0 0] (exp) and not y1_pred.
Now the output at time-step 2 will be some random vector y2_pred. But at time-step 3 we will be using input as y2_true = [0 0 1 0 0 0] (==) and not y2_pred. Similarly at each time-step, we will use the true output from the previous time-step.
Finally, the loss is calculated on the predicted outputs from each time-step and the errors are backpropagated through time to update the parameters of the model.
Decoder in test phase: In a real-world application, we won’t have Y_true but only X. Thus when testing our model, the predicted output (and not the true output unlike the training phase) from the previous time-step is fed as input to the current time-step.
Results
The model evaluation is performed based on the total types of codes that have a maximum of errors from certain groups being corrected by the forward and backward model. The error groups considered are :
- Indentation error
- Parenthesis error
- Other syntax errors indicated using exceptions and errors by the parse tree evoked from the os library. Theses include incorrect use of symbols, missing symbols, i.e. invalid syntax errors.
Accuracy
- Forward Corrector: 76.2%
- Backward Corrector: 67.2%
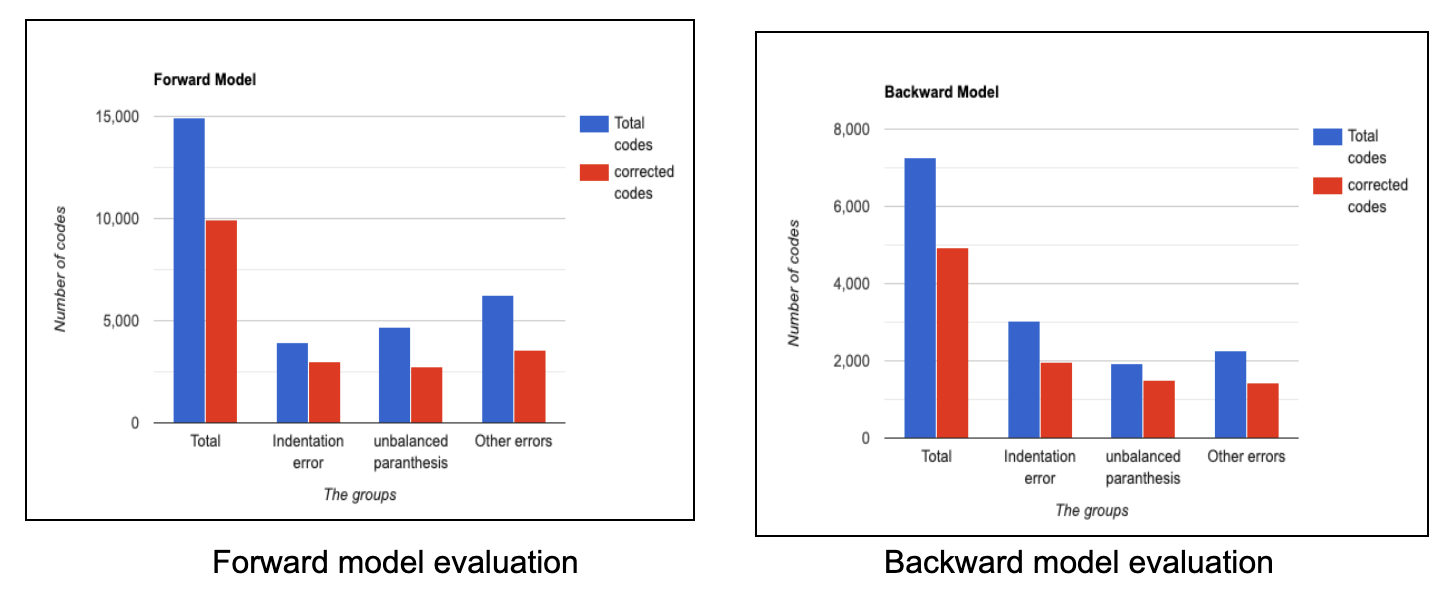
The above figure shows the accuracy of the forward corrector and backward corrector. The X axis represents the code groups(indentation, unbalanced parenthesis, others) and the Y axis represents the number of codes taken under consideration. The blue bar depicts the codes of particular type taken under consideration and the red bar indicates the number of codes that were corrected by the proposed system. The trained forward corrector has the highest accuracy of 92% for missing parenthesis errors, 56% for indentation errors and 87% for other errors. For the backward corrector model, the missing parenthesis accuracy is 79%, 64% for indentation errors and 63% for other errors.
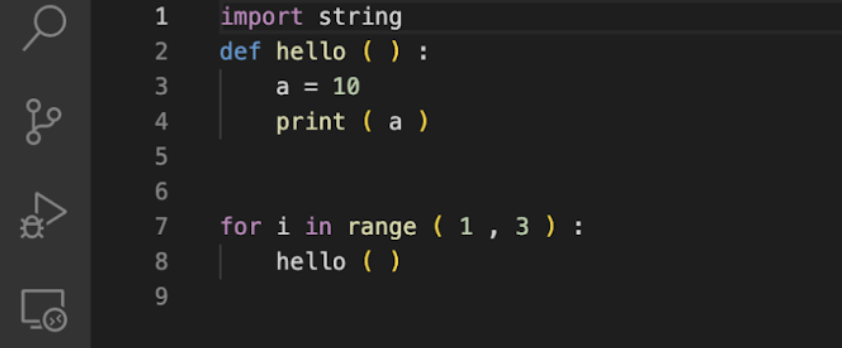
UI

Incorrect Code File

Corrected Code